光学字符识别(OCR)技术已广泛应用于印刷体文字转换,但其处理矢量图文件(如SVG、PS格式)时存在明显局限:需先将矢量图渲染为位图,效率低且难以兼顾速度与精度,更无法识别字符所用的具体字体。
词袋模型(BoW)源自文本分类,将文档表示为特征矢量集合,忽略词序与语法。该模型被引入图像检索后,可与ORB等视觉特征结合,实现快速相似图搜索。
近日,合肥高维数据技术有限公司公开了一项名为“基于词袋模型特征点检索的矢量字符识别方法及系统”的发明专利(申请号:202111466725.6),提出了一种不依赖渲染、直接识别矢量字符的新方案,在识别速度、准确率和字体识别能力上均实现了显著突破。
一、核心技术:从控制点到词袋检索
该专利的核心思路是:不将矢量图转为图像,而是直接读取其轮廓信息。具体步骤如下:
解析控制点:从字符矢量图中提取轮廓信息,转化为控制点坐标;
生成控制点灰度图:将控制点坐标绘制成统一尺寸(如128×128像素)的灰度图;
提取ORB特征:基于灰度图提取ORB特征矢量;
词袋树检索:将特征矢量输入预先构建的词袋树索引,快速匹配最相似的字符ID;
映射字符信息:通过字符ID反查对应的字体和Unicode编码。
其中,视觉词典和词袋树索引是通过对多个常用字体(如宋体、楷体等)中的每个字符预先提取ORB特征,并采用词袋模型算法(如DBoW2、DBoW3)聚类构建而成。
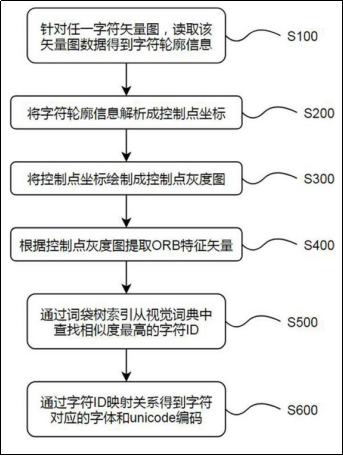
本发明的流程示意图
二、三大优势:准、快、懂字体
与传统OCR方法相比,该方案在以下三个方面表现尤为突出:
1、识别范围广,准确率高
支持GB2312字符集全部6763个汉字,并可扩展至更大字符集;对训练字体范围内的字符识别正确率达到100%。
2、识别速度快,毫秒级响应
单字识别速度约1.5ms;以一页700字计算,整页识别仅需约1秒,远优于主流OCR方法的5~6秒/页。
3、同时识别字体,填补行业空白
除特征点极少的字符(如“、”或“”)外,均可准确判断字体类型;这一能力在隐形水印嵌入、字体敏感任务中具有重要价值。
三、系统化实现,便于部署
该专利还配套提出了一套完整的识别系统,包括:控制点坐标计算模块、制图模块、ORB特征提取模块、词袋树检索模块、字符ID映射查询模块。
视觉词典与词袋树索引可保存为数据库文件,便于迁移与复用。系统可运行于通用计算设备,并支持计算机可读存储介质及电子设备上的程序执行。
四、适用场景广泛
该技术特别适用于以下场景:
隐形水印嵌入与解析:根据字体类型进行操作的任务,如文档溯源。
矢量图(如SVG、PS)文档自动识别:无需渲染为位图,直接读取轮廓信息,识别字符及字体。
保留字体信息的文字提取:识别结果同时包含字体与Unicode,便于后续处理。
大规模字符库快速检索:词袋树索引支持毫秒级匹配,可扩展至更大字符集。
五、结论
这项专利提出了一条与OCR截然不同的技术路径:不渲染、不比对图像,而是直接利用矢量图的控制点结构,结合词袋模型实现高效检索。它在识别速度、准确率和字体识别能力上均展现出明显优势,为矢量字符识别领域提供了一种全新的思路。
如果您所在的企业或项目正面临矢量图中字符识别的效率或精度瓶颈,这项技术无疑值得关注。
技术交流与合作洽谈:请致电 0551-67122296
关注我们:获取更多【专利解读】与技术干货
分享本文:让更多面临同样安全挑战的伙伴看到它!
- END -